Mystery Math Whiz and Novelist Advance Permutation Problem
A new proof from the Australian science fiction writer Greg Egan and a 2011 proof anonymously posted online are now being hailed as significant advances on a puzzle mathematicians have been studying for at least 25 years.
On September 16, 2011, an anime fan posted a math question to the online bulletin board 4chan about the cult classic television series The Melancholy of Haruhi Suzumiya. Season one of the show, which involves time travel, had originally aired in nonchronological order, and a re-broadcast and a DVD version had each further rearranged the episodes. Fans were arguing online about the best order to watch the episodes, and the 4chan poster wondered: If viewers wanted to see the series in every possible order, what is the shortest list of episodes they’d have to watch?
In less than an hour, an anonymous person offered an answer — not a complete solution, but a lower bound on the number of episodes required. The argument, which covered series with any number of episodes, showed that for the 14-episode first season of Haruhi, viewers would have to watch at least 93,884,313,611 episodes to see all possible orderings. “Please look over [the proof] for any loopholes I might have missed,” the anonymous poster wrote.
The proof slipped under the radar of the mathematics community for seven years — apparently only one professional mathematician spotted it at the time, and he didn’t check it carefully. But in a plot twist last month, the Australian science fiction novelist Greg Eganproved a new upper bound on the number of episodes required. Egan’s discovery renewed interest in the problem and drew attention to the lower bound posted anonymously in 2011. Both proofs are now being hailed as significant advances on a puzzle mathematicians have been studying for at least 25 years.
Mathematicians quickly verified Egan’s upper bound, which, like the lower bound, applies to series of any length. Then Robin Houston, a mathematician at the data visualization firm Kiln, and Jay Pantone of Marquette University in Milwaukee independently verified the work of the anonymous 4chan poster. “It took a lot of work to try to figure out whether or not it was correct,” Pantone said, since the key ideas hadn’t been expressed particularly clearly.
Now, Houston and Pantone, joined by Vince Vatter of the University of Florida in Gainesville, have written up the formal argument. In their paper, they list the first author as “Anonymous 4chan Poster.”
“It’s a weird situation that this very elegant proof of something that wasn’t previously known was posted in such an unlikely place,” Houston said.
Permutation Cities
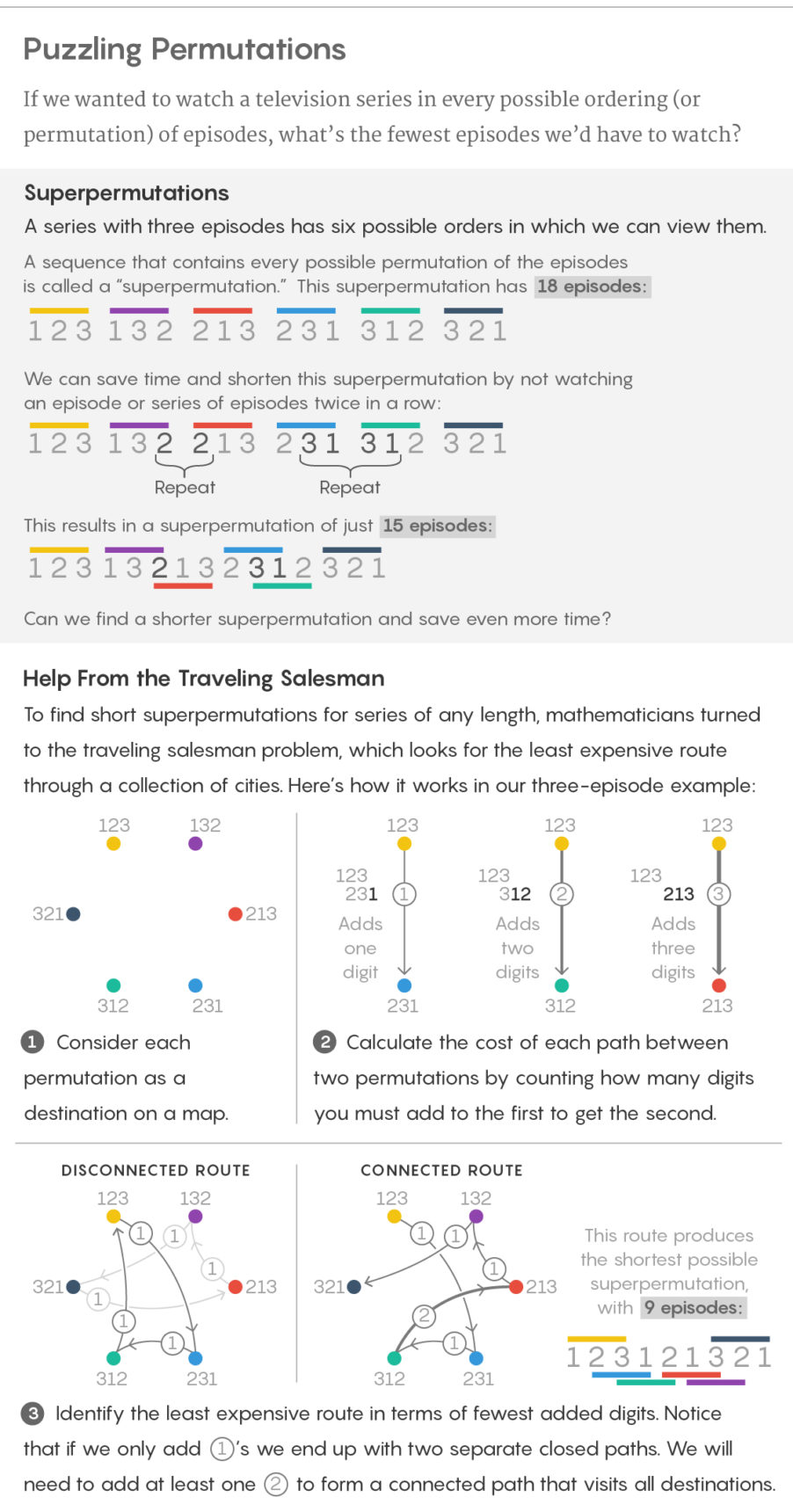
If a television series has just three episodes, there are six possible orders in which to view them: 123, 132, 213, 231, 312 and 321. You could string these six sequences together to give a list of 18 episodes that includes every ordering, but there’s a much more efficient way to do it: 123121321. A sequence like this one that contains every possible rearrangement (or permutation) of a collection of n symbols is called a “superpermutation.”
In 1993, Daniel Ashlock and Jenett Tillotson observed that if you look at the shortest superpermutations for different values of n, a pattern quickly seems to emerge involving factorials — those numbers, written in the form n!, that involve multiplying together all the numbers up to n (for example, 4! = 4 × 3 × 2 × 1).
If your series has just one episode, the shortest superpermutation has length 1! (also known as plain old 1). For a two-episode series, the shortest superpermutation (121) has length 2! + 1!. For three episodes (the example we looked at above), the length works out to 3! + 2! + 1!, and for four episodes (123412314231243121342132413214321), it is 4! + 3! + 2! + 1!. The factorial rule for superpermutations became conventional wisdom (even though no one could prove it was true for every value of n), and mathematicians later confirmed it for n = 5.
Then in 2014, Houston startled mathematicians by showing that forn = 6, the pattern breaks down. The factorial rule predicts that to watch six episodes in every possible order should require 873 episodes, but Houston found a way to do it in 872. And since there is a simple way to convert a short superpermutation on n symbols into a short superpermutation on n + 1 symbols, Houston’s example meant that the factorial rule fails for every value of n above 6 too.
Houston’s construction works by translating the superpermutation problem into the famous traveling salesman problem, which looks for the shortest route through a collection of cities. More specifically, superpermutations are connected to the “asymmetric” traveling salesman problem, in which each path between two cities has a cost (which is not necessarily the same in both directions), and the goal is to find the least expensive route through all the cities.
The translation is simple: Think of each permutation as a “city” and imagine a path from each permutation to each other permutation. In the superpermutation problem, we want the shortest possible sequence of digits that lists all the permutations, so the goal is to travel through the permutations in a way that adds as few digits to the starting permutation as possible. So we declare the cost of each path to be simply the number of digits we have to attach to the end of the first permutation to get the second one. In the n = 3 example, for instance, the path from 231 to 312 costs $1, since we just have to add a 2 to the end of 231 to get 312, while the path from 231 to 132 costs $2, since we have to add a 32. With this setup, the least-expensive path through the cities corresponds directly to the shortest superpermutation.
Lucy Reading-Ikkanda/Quanta Magazine
This translation meant that Houston could turn the power of traveling salesman algorithms on the superpermutation problem. The traveling salesman problem is famous as an NP-hard problem, meaning that there’s no efficient algorithm that can solve all cases of it. But there are algorithms that can solve some cases efficiently, and other algorithms that produce good approximate solutions. Houston used one of the latter to produce his 872-digit superpermutation.
Since he produced only an approximate solution, it might not be the very best superpermutation. Mathematicians are now conducting a giant computer search for the shortest superpermutation on six symbols, Pantone said. “We know our search will finish in finite time, but don’t know if that’s one week or a million years,” he said. “There’s no progress bar.”
The Wrong Order
By the time of Houston’s work, the anonymous 4chan post had been sitting in its corner of the internet for nearly three years. One mathematician, Nathaniel Johnston of Mount Allison University, had noticed a copy of the post on a different website a few days after it was posted — not because he was an anime fan, but because he had typed an assortment of superpermutation-related search terms into Google.
Johnston read the argument and thought it seemed plausible, but he didn’t invest much effort in checking it carefully. At the time, mathematicians believed that the factorial formula for superpermutations was probably correct, and when you think you know the exact answer to a question, a lower bound isn’t very interesting. In other words, the superpermutation research episodes were playing out of order.
Johnston later mentioned the lower bound on a couple of websites, but “I don’t think anyone really gave it any particular heed,” Houston said.
Then on September 26 of this year, the mathematician John Baez of the University of California, Riverside, posted on Twitter about Houston’s 2014 finding, as part of a series of tweets about apparent mathematical patterns that fail. His tweet caught the eye of Egan, who was a mathematics major decades ago, before he launched an award-winning career as a science fiction novelist (his breakthrough 1994 novel, in a happy coincidence, was called Permutation City). “I’ve never stopped being interested in [mathematics],” Egan wrote by email.
Egan wondered if it was possible to construct superpermutations even shorter than Houston’s. He scoured the literature for papers on how to construct short paths through permutation networks, and after a few weeks found exactly what he needed. Within a day or two, he had come up with a new upper bound on the length of the shortest superpermutation for n symbols: n! + (n – 1)! + (n – 2)! + (n – 3)! + n – 3. It’s similar to the old factorial formula, but with many terms removed.
“It absolutely smashed the [previous] upper bound,” Houston said.
The anonymous 4chan poster’s lower bound, meanwhile, was tantalizingly close to the new upper bound: It works out to n! + (n – 1)! + (n – 2)! + n – 3. When Egan’s result became public, Johnston reminded other mathematicians about the anonymous poster’s proof, and Houston and Pantone soon showed it was correct. As with Houston’s work, the new lower and upper bounds both come at superpermutations via the traveling salesman problem: The lower bound shows that a route through all the cities must travel along some minimum number of paths that cost more than $1, while the upper bound constructs a specific route for each n that uses only $1 and $2 connections.
Researchers are now trying to bring the upper and lower bounds together to find a single formula that solves the superpermutation problem. “Probably people are eventually going to completely nail down this puzzle,” Baez predicted. “It’s looking good now.”
For Haruhi fans, Egan’s construction gives explicit instructions for how to watch all possible orderings of season one in just 93,924,230,411 episodes. Viewers could start binge-watching immediately, or they could wait and see whether mathematicians can whittle this number down. The anonymous poster’s lower bound proves that this whittling down couldn’t possibly save more than about 40 million episodes — but that’s enough to get a nice start on season two.
In the Nucleus, Genes’ Activity Might Depend on Their Location Using a new CRISPR-based technique, researchers are examining how the position of DNA within the nucleus affects gene expression and cell function. A new CRISPR-based technology allows researchers to control the spatial organization of DNA inside the nucleus of a cell.
The nucleus of a cell has something in common with a cardboard box full of kittens: People get so fascinated by the contents that they overlook the container. The nucleus itself is often treated as no more than a featureless membranous bag for holding the vitally dynamic genetic material. Yet in fact it has specialized parts and an internal architecture of its own, and scientists have long speculated that precisely how the DNA positions itself with respect to those parts might matter a great deal.
Now a team of researchers is finding credible evidence that this is true and possibly an important influence on gene expression. Using a new technique based on the genome-editing tool CRISPR, they artificially pinned parts of a cell’s DNA to different regions in the nucleus and observed what happened. The work, published last month in Cell, has begun to yield intriguing insights into how various nuclear neighborhoods may relate to gene expression, as either cause or facilitator.
The 6 feet of DNA intricately bundled within a human cell’s tiny nucleus can look as chaotic as a ball of spaghetti or a tangle of thread. But how that DNA gets situated in three-dimensional space is critical — and not at all random. The degree of packing and folding enables genes to be accessible in the right place at the right time, so that the cell’s machinery can find and decode them, dial their activity up or down, and keep everything working as it should. Those rearrangements also put specific parts of the genome near or far from landmarks within the nucleus.
There’s been tantalizing evidence that the positioning of DNA at those nuclear locations may not be coincidental. Tightly wound, silent genes tend to be located toward the periphery of the nucleus, while open, active DNA makes its home toward the interior. During development, as cells differentiate, the DNA reorganizes itself: As some genes shift from a repressed state to an active one, they’ve also been found to move away from the periphery. That said, some other gene regions usually found near the periphery aren’t there all the time, and when they do move, they still show the same levels of activity.
Biologists have therefore debated how DNA’s condensed structure and expression relate to its nuclear location, and what might be cause rather than effect. Inactive genes with a certain profile might get drawn to the periphery, or the periphery itself may be responsible for silencing them. Those considerations get even more complicated toward the center of the nucleus, which comprises many different domains defined by a variety of nuclear bodies, such as the nucleolus (which assembles ribosomes for protein production) and Cajal bodies (which help to splice RNA). Their functions, too, have been difficult to tease apart: Once again, correlations abound, but pinning down causality is a different story.
Stanley Qi, a bioengineer at Stanford University, holds a 3D printed model of the modified CRISPR complex that he and his team created to help move DNA to chosen regions of the nucleus.
“These have been the questions at the epicenter of the studies on the relationship of genome organization and nuclear structure and gene regulation for decades,” said Mitchell Guttman, a biologist at the California Institute of Technology.
And so for the past four years, Stanley Qi, a bioengineer at Stanford University, and his colleagues have been working on paving a way for scientists to start answering those questions. They turned to CRISPR, a system that has been used widely to edit genes, regulate transcription and take images of cellular processes. Now they’ve innovated a way to harness it for spatial control over the genome. They’ve dubbed the process CRISPR-GO (the GO stands for “genome organization”). “It’s a broad expansion of the CRISPR technology,” Qi explained, “which started five years ago and is still not slowing down.”
The method works a bit like placing a strip of Velcro on the genes the researchers want to move, and another strip on the nuclear body they want to move the genes to. As the DNA passes by, the two corresponding pieces of Velcro end up sticking together.
More specifically, the scientists employ the molecular complex CRISPR/Cas9 — its ability to cut the genome deactivated — to target a specific DNA sequence. Part of a protein is attached to the complex, and a second part is attached to a chosen structure within the nucleus. As the DNA goes about its business, moving and shifting as usual, the researchers add an “inducer” molecule that links to both protein fragments, binding them and tethering the DNA to the new location. Removing the inducer frees the DNA to move away again.
Lucy Reading-Ikkanda/Quanta Magazine
Previously, researchers had used another technique to try to achieve this result. However, they had to engineer a special cell line to integrate a long, highly repetitive bacterial or synthetic sequence next to a gene of interest. The system was difficult to use and limited in scope, and the invasive nature of the method meant the experiment itself could be affecting the results. When such studies yielded inconsistent findings — some concluded that recruiting DNA to the nuclear periphery led to gene silencing, for instance, while others saw no such effect — researchers struggled to interpret them.
But CRISPR-GO doesn’t require scientists to modify the genome, and it can precisely target any region of DNA. “It’s in a way a much gentler approach,” said David Spector, a molecular biologist at Cold Spring Harbor Laboratory in New York, who was not involved in this work. “And more elegant.”
With CRISPR-GO, scientists now have the toolbox to explore what nuclear bodies are really doing: how they may or may not be influencing the activity of specific genes, for one, and what roles they might be playing in health and disease.
Qi and his team showed how that can work. They first noted that different nuclear bodies exhibited their own dynamics. When they repositioned DNA to the nuclear periphery, for example, it was the DNA that did the moving, and the process took nearly a day. But when they relocated sections of the genome to a Cajal body, the latter went to the former within only a few minutes. According to Qi, those findings could reveal information about how long-lasting or transient activation and repression may be in certain parts of the nucleus, and about how actively DNA interactions are maintained.
As previous work had also shown, Qi and his colleagues observed that a spatial relationship seemed to exist for some genes and not others. Still, they uncovered some surprising links, including long-range effects. Moving some protein-coding genes to a Cajal body, for example, suppressed their activity — as well as that of DNA located hundreds of kilobases away.
The team also looked at noncoding regions of genes, sequences with regulatory or other functions that make up the vast majority of DNA. They focused specifically on telomeres, sections of DNA located at the tips of chromosomes that relate to cellular life span. When the telomeres were repositioned to the nuclear periphery, cell division ground almost to a halt. Moving the telomeres close to the Cajal bodies, though, had just the opposite effect, causing cells to grow and divide much more rapidly.
“This implies that the location of the telomeres in the nucleus is important for cells to finish their proper cell cycle,” Qi said. He speculates that the Cajal bodies may have had this effect because they’ve previously been shown to produce an enzyme that helps maintain the length of telomeres. “We think we were potentially co-localizing the manufacturing plant with the consumer market,” he said.
But the researchers still need to root out just why these effects occurred. They’ll have to perform further experiments — targeting various genes and nuclear bodies in diverse cell types, and testing not only for effects on gene expression but also on genomic stability and other factors — to find out why and how the genome is organized as it is. At the very least, it seems to “build in an extra level of control,” Guttman said. “By creating active and inactive territories, the nucleus can prevent proteins that silence transcription from aberrantly turning off a gene that needs to be on, and vice versa.”
Susan Gasser, a molecular biologist at the Friedrich Miescher Institute for Biomedical Research in Switzerland, thinks experts will find that location in the nucleus is important for very particular processes, such as DNA repair — but that a lot of the time, “it instead fine-tunes gene expression.” The open or condensed state of the DNA itself may be more influential. Still, CRISPR-GO can be used to test that idea, she said.
It can also help investigate the role of nuclear organization in development and disease. Pathologists have been using nuclear morphology as a diagnostic tool for a long time: Altered states and distributions of DNA correlate with cancer and other conditions, as does an increase in the number of certain nuclear bodies. But it’s been unclear if those are the results of the disease or its cause.
Now Qi feels that he and others are in a position to find out. One day, he said, the system might be used not just for exploration and basic research, but as a means of treatment as well.
Even so, some experts still have reservations. Andrew Belmont, a cell biologist at the University of Illinois at Urbana-Champaign, cautions that the researchers still need to confirm that their technique accurately reflects natural processes in the cell, and not some artificial consequence of the tethering procedure. He and his colleagues, along with a few other groups, have developed alternative systems to get around that concern, which involve inserting natural sequences into targeted DNA regions that are already ordinarily associated with one nuclear body or another. Still, he agrees that CRISPR-GO represents a major step forward.
Guttman concurred. “I anticipate that this will become an incredibly powerful tool for many in the field to start deciphering those really old and really important questions,” he said.
Scientists Create Artificial Wood That Is Water- and Fire-Resistant The synthetic material is faster to make than natural wood
Credit: From “Bioinspired Polymeric Woods,” by Zhi-Long Yu et al., in Science Advances, Vol. 4, No. 8; August 10, 2018
A new lightweight substance is as strong as wood yet lacks its standard vulnerabilities to fire and water.
To create the synthetic wood, scientists took a solution of polymer resin and added a pinch of chitosan, a sugar polymer derived from the shells of shrimp and crabs. They freeze-dried the solution, yielding a structure filled with tiny pores and channels supported by the chitosan. Then they heated the resin to temperatures as high as 200 degrees Celsius to cure it, forging strong chemical bonds.
The resulting material, described in August in Science Advances, is as crush-resistant as wood, says author Shu-Hong Yu, a materials chemist at the University of Science and Technology of China in Hefei. Faster freeze-drying creates even smaller channels and pores, which further strengthens the material, Yu says. And higher curing temperatures increase bonding within the resin and increase the material's strength, the team found. Adding human-made or natural fibers to the mix could also help.
Unlike natural wood, the new material does not require years to grow. Moreover, it readily repels water—samples soaked in water and in a strong acid bath for 30 days scarcely weakened, whereas samples of balsa wood tested under similar conditions lost two thirds of their strength and 40 percent of their crush resistance. The new material was also difficult to ignite and stopped burning when it was removed from the flame.
The mock wood could be used to make ding-resistant packaging, says Lennart Bergström, a materials scientist at Stockholm University in Sweden, who was not involved in the work. Its porosity lends an air-trapping capacity that could make it suitable as an insulation for buildings, he adds. Eco-friendly alternatives to the polymer resins also could boost interest in the material.
Happy with a 20% Chance of Sadness Researchers are developing wristbands and apps to predict moods—but the technology has pitfalls as well as promise
In the winter of 1994, a young man in his early twenties named Tim was a patient in a London psychiatric hospital. Despite a happy and energetic demeanour, Tim had bipolar disorder and had recently attempted suicide. During his stay, he became close with a visiting US undergraduate psychology student called Matt. The two quickly bonded over their love of early-nineties hip-hop and, just before being discharged, Tim surprised his friend with a portrait that he had painted of him. Matt was deeply touched. But after returning to the United States with portrait in hand, he learned that Tim had ended his life by jumping off a bridge.
Matthew Nock now studies the psychology of self-harm at Harvard University in Cambridge, Massachusetts. Even though more than two decades have passed since his time with Tim, the portrait still hangs in his office as a constant reminder of the need to develop a way to predict when people are likely to try and kill themselves. There are plenty of known risk factors for suicide—heavy alcohol use, depression and being male among them—but none serve as tell-tale signs of imminent suicidal thoughts. Nock thinks that he is getting close to solving that.
Since January 2016, he has been using wristbands and a phone application to study the behaviour of consenting patients who are at risk of suicide, at Massachusetts General Hospital in Boston. And he has been running a similar trial at the nearby Franciscan Children’s Hospital this year. So far, he says, although his results have not yet been published, the technology seems able to predict a day in advance, and with reasonable accuracy, when participants will report thinking of killing themselves.
Nock’s trial is one effort to make use of the burgeoning science of mood forecasting: the idea that by continuously recording data from wearable sensors and mobile phones, it will be possible not only to track and perhaps identify signs of mental illness in a person, but even to predict when their well-being is about to dip. Nock collaborates with Rosalind Picard, an electrical engineer and computer scientist at the Massachusetts Institute of Technology (MIT) in Cambridge. Picard leads a team that has tracked hundreds of undergraduates in universities in New England with phones and wristbands, and reports being able to predict episodes of sadness in these students a day before symptoms arrive.
Hints that it might be possible to track impending emotional vulnerability have sparked strong commercial interest. Mindstrong Health, a company in Palo Alto, California, which has raised US$29 million in venture capital, tracks how people tap, type and scroll on their phones, to spot shifts in neurocognitive function. Paul Dagum, a physician and computer scientist who founded the firm, says that data from a person’s touchscreen interactions can identify oncoming episodes of depression, although that work has not yet been published. Other companies are also researching the use of such ‘digital phenotyping’ to recognize symptoms of mental illness. Among them is Verily, a life-sciences firm owned by Google’s parent company, Alphabet.
At this stage, the reliability of mood-prediction technology is unclear. Few results have been published, and groups that have released results say they have achieved only moderate rather than outstanding accuracy when it comes to forecasting moods. Picard, however, is confident that the concept will hold up. “I suffered from depression early in my career and I do not want to go back there,” she says. “I am certain that by tracking my behaviours with my phone I can make it far less likely I will return to that terrible place.”
But researchers including Picard have reservations about possible downsides of their creations. They worry that scientists and clinicians haven’t thought enough about how to inform users of an imminent emotional downturn. There are also questions about whether such warnings could cause harm. And some wonder whether corporations or insurance companies might use the technology to track the future mental health of their employees or customers. “The [potential for] misuse of this technology is what keeps me up at night,” Dagum says.
PREDICTING DEPRESSION
Picard got into mood-prediction research indirectly. A decade ago, she showed that it was possible to use wristbands to detect seizures, sometimes minutes before spasms shook the body, by tracking the electrical conductance on a person’s skin. In 2013, she co-founded Empatica, a company in Cambridge that sells sensors, including a smartwatch approved by the US Food and Drug Administration to monitor signs of seizures and issue alerts to caregivers.
Working with her PhD student at the time Akane Sano, now at Rice University in Houston, Texas, Picard saw potential for wider applications. They hypothesized that it might be possible to combine data from wrist sensors and mobile phones to monitor stress, sleep, activity and social interactions to predict general mental health and well-being.
Sano and Picard collaborated with a team at Harvard Medical School to design a study that would track university students on a daily basis. Since 2013, the team has studied 300 students—50 each semester, for 30 days at a time—by giving them watch-like devices to wear. The instruments measure the students’ movements, note the amount of light they are exposed to, monitor their body temperature and record the electrical conductance of their skin. Sano and Picard also developed software, installed on participants’ phones, which records data about their calls, text messages, location, Internet use, ‘screen on’ timing and social interactions. The team also recorded much of their e-mail activity. Students filled out surveys twice a day about their academic, extracurricular and exercise activities. They described their sleep quality, their mood, health, stress levels, social interactions and how many caffeinated and alcoholic drinks they were consuming. The students also reported their exam scores and filled out extensive surveys at the beginning and end of the 30-day studies.
By 2017, the team had reported, training an algorithm to learn from these surveys and to weight the importance of hundreds of measurements. The system can accurately forecast, a day in advance, the students’ happiness, calmness and health, Picard’s team says. In the experiment, individuals had to be monitored for 7 days to reach forecast-accuracy levels of around 80%. Picard’s analysis suggests that wristbands and mobile phones are not able to predict slight changes in mood. But when changes in well-being are large, predictions are more reliable. Some of the signals make intuitive sense—moving around before bed might suggest agitation, for instance—but the details are not always understood. As an example, social interactions might modify stress levels, which can be reflected in skin electrical conductance, but it’s unclear whether many peaks of skin conductance in a day is good or bad, because it increases both when people are problem solving and when they are stressed.
Simply interpreting someone’s mood using such signals is a great achievement, says computer scientist Louis-Philippe Morency at Carnegie Mellon University in Pittsburgh, Pennsylvania, who thinks artificial-intelligence technology could help with mental-health assessments. But he is cautious about its ability to forecast moods. “Since tomorrow’s mood is often similar to today’s mood, we need more research to be able to clearly decouple these two phenomena. It is possible that current forecasting technologies are mostly predicting spillover emotion from one day to the next,” he says.
Picard thinks improvements will come: “We are the pioneers saying that this is truly possible and are showing data to back this claim up. Reliability will grow and grow with more data.” She has made her algorithms open-source, so that others with access to the technology can try to reproduce her work.
“Picard is on to something, and her track record of transparency with her algorithms, models and data sets makes me even more confident of that. People don’t make it so easy to recreate their work when they are unsure about their results,” says Jonathan Gratch, a psychologist at the Institute for Creative Technologies at the University of Southern California in Playa Vista.
Nock’s trial on suicidal thoughts grew out of a collaboration with Picard. So far, he has monitored 192 people, mainly using wristbands and by asking them how they are feeling, through a phone app or interview. For now, he has trained devices not on an individual’s data, but on those of the entire group of participants, and he says that he has identified a few measurable signs that can predict later suicidal thoughts with an accuracy of 75%. Some of the most important factors, he says, are considerable movement in the evening, perhaps denoting restlessness or agitation at night, mixed with spikes in skin electrical conductance and an elevated heart rate. But he declined to give more details because his paper is under review at a journal.
MOVING TO MARKET
Commercial firms are less willing than are academics to discuss their results. But in March, Mindstrong, which is only 16 months old, reported finding digital biomarkers — patterns of swipes and taps on a phone—that correlate with scores on neuropsychological performance tests3. On its website, the firm says it has completed five clinical trials, the results of which have not been disclosed, and in February, it announced a partnership with Tokyo-based Takeda Pharmaceuticals to explore the development of digital biomarkers for conditions such as schizophrenia and treatment-resistant depression. It has competition: Verily says its digital phenotyping projects include one designed to detect post-traumatic stress disorder using smartphones and watches.
Mindstrong says it’s moving beyond measuring brain function with smartphones, to predicting it. “When we take in the trajectory of numerous biomarkers over the course of six or seven days, we can predict episodes of depression up to a week in the future,” says Dagum—although he declined to say which signals his firm is using, because the company was submitting papers on its work to journals.
The plan for Mindstrong’s phone-based app (the company is not using wristbands) is to embed its touchscreen-interaction measures into a digital mental-health-care system. It has been sharing results with the state of California, which sees enough clinical potential to have granted the firm $10 million over 3 years from a state-managed, $60-million mental-health innovation fund. “Will all of this data that we are collecting ultimately have clinical utility? We don’t know yet,” says psychiatrist Tom Insel, who co-founded Mindstrong and had previously started the mental-health unit at Verily after a 13-year stint as head of the US National Institute of Mental Health.
Picard questions Insel’s approach at Mindstrong. “I believe he has made a company with an idea that is not proven to work as well as other ideas,” she says. Neither she nor Nock yet have commercial plans for their mood-prediction technology. (Besides Empatica, however, Picard has co-founded Affectiva, a firm in Boston that sells technology to analyse facial and vocal expressions.)
Insel says the technology needs testing in real-world settings, with patients and health providers. “We are not running before walking. California is paying us to learn how to walk,” he says. He adds that he doesn’t view Picard as a rival. “This is a hard problem that no one has solved. My best guess is that it will take all of us using many approaches to prove the clinical value of this technology—and, frankly, I’d love to have at least ten other groups of Roz’s lab’s calibre working on digital phenotyping,” he says.
CHANGING BEHAVIOUR
Picard is confident that mood forecasting—even if it requires individualized training from a consenting user—will become a perfected art. The real question, she says, is whether it can be used to help change a forecasted dark mood.
Nock and psychologist Evan Kleiman, also at Harvard University, are working with 150 patients to encourage them to reappraise things that they are viewing negatively by using cognitive reframing exercises. These exercises are activated on the patients’ phones when their wrist monitors detect signals that predict upcoming suicidal thoughts. Beyond this, Nock is unclear what to do with the data. “If we have someone who is predicted to be at high risk for suicidal thoughts, or who notes that they are 100% likely to kill themselves, what do we do? Do we send an ambulance? Contact their doctor? Do nothing?” he wonders. “The ethics of this are extremely challenging.” Nock says he knows that those in his trial want the technology. “Patients say all the time how useful they would find an alert or guidance system,” he says.
Morency thinks that it is too soon for computers to be giving mental-health advice on their own. His research involves teaching computers to study facial expressions and language so that they can work out what is on a person’s mind, and he is now collaborating with psychiatrists to install this technology in hospital mental-health wards. The goal is for machines to study people during their interactions with doctors, to discern whether psychiatric disorders are present. The physicians still do the diagnosis; the computer analysis provides a separate assessment that doctors can compare with their own. “The risks presented by a computer giving mental-health advice are significant. We need more research to understand the long-term impact of such technology,” Morency says.
Another issue, says Picard, is that actions to improve mood are different for different people. In one of her experiments, Picard found that one cluster of students who had conversations with friends before going to sleep enjoyed brighter moods the following day, whereas another cluster experienced the inverse effect.
Barbara Fredrickson, a psychologist at the University of North Carolina at Chapel Hill, is concerned that the act of predicting a mood could affect how people feel. “It seems likely that people will give negative mood forecasts a great deal of attention, and for some, this could start an emotional negativity tailspin that could be truly damaging,” she says.
Justin Baker, a researcher in mental illnesses who is the scientific director of the McLean Institute for Technology in Psychiatry in Belmont, Massachusetts, says: “I think it will be just as difficult for us to determine what advice a person needs as it will be to determine how to present that advice to them in a manner that does not get ignored or make them worse.”
Picard has grand visions for digital mood forecasting. She thinks it could improve the health of the general public, and in particular that it might benefit corporations. “Why do so many amazing companies that give their employees every perk under the sun still lose so many staff to depression? Can we catch the coming transition before it takes place?” she says. But she also worries that the technology might be misused. Picard thinks that new regulations might be needed to prevent, say, corporations from targeting advertising at those whose bad or good moods can be seen coming, or to keep insurance companies from setting prices based on signs of their customers’ mental health.
“A few bad actors who misuse this technology could spoil the benefits for patients with serious mental-health issues,” says Insel. Mindstrong, he says, is working with a bioethics group at Stanford University, California and plans to publish a paper on these matters shortly.
Picard argues the research efforts are worthwhile. “Clinical depression is often emotional death by a thousand cuts,” she says. “If we can help to identify the many little things that weigh us down over time and drive us into a perpetual sorrowful state, we can make a big difference.”
It might sound scary, but the ‘dark web’ is not much different from the rest of the internet
The following essay is reprinted with permission fromThe Conversation, an online publication covering the latest research.
In the wake of recent violent events in the U.S., many people are expressing concern about the tone and content of online communications, including talk of the “dark web.” Despite the sinister-sounding phrase, there is not just one “dark web.” The term is actually fairly technical in origin, and is often used to describe some of the lesser-known corners of the internet. As I discuss in my new book, “Weaving the Dark Web: Legitimacy on Freenet, Tor, and I2P,” the online services that make up what has become called the “dark web” have been evolving since the early days of the commercial internet—but because of their technological differences, are not well understood by the public, policymakers or the media.
As a result, people often think of the dark web as a place where people sell drugs or exchange stolen information—or as some rare section of the internet Google can’t crawl. It’s both, and neither, and much more.
SEEKING ANONYMITY AND PRIVACY
In brief, dark websites are just like any other website, containing whatever information its owners want to provide, and built with standard web technologies, like hosting software, HTML and JavaScript. Dark websites can be viewed by a standard web browser like Firefox or Chrome. The difference is that they can only be accessed through special network-routing software, which is designed to provide anonymity for both visitors to websites and publishers of these sites.
Websites on the dark web don’t end in “.com” or “.org” or other more common web address endings; they more often include long strings of letters and numbers, ending in “.onion” or “.i2p.” Those are signals that tell software like Freenet, I2P or Tor how to find dark websites while keeping users’ and hosts’ identities private.
Those programs got their start a couple of decades ago. In 1999, Irish computer scientist Ian Clarke started Freenet as a peer-to-peer systemfor computers to distribute various types of data in a decentralized manner rather than through the more centralized structure of the mainstream internet. The structure of Freenet separates the identity of the creator of a file from its content, which made it attractive for people who wanted to host anonymous websites.
Today, the more commonly used internet has billions of websites—but the dark web is tiny, with tens of thousands of sites at the most, at least according to the various indexes and search engines that crawl these three networks.
A MORE PRIVATE WEB
The most commonly used of the three anonymous systems is Tor – which is so prominent that mainstream websites like Facebook, The New York Times and The Washington Post operate versions of their websites accessible on Tor’s network. Obviously, those sites don’t seek to keep their identities secret, but they have piggybacked on Tor’s anonymizing web technology in order to allow users to connect privately and securely without governments knowing.
In addition, Tor’s system is set up to allow users to anonymously browse not only dark websites, but also regular websites. Using Tor to access the regular internet privately is much more common than using it to browse the dark web.
MORAL ASPECTS OF ‘DARK’ BROWSING
Given the often sensationalized media coverage of the dark web, it’s understandable that people think the term “dark” is a moral judgment. Hitmen for hire, terrorist propaganda, child trafficking and exploitation, guns, drugs and stolen information markets do sound pretty dark.
Even complaining that dark web information isn’t indexed by search engines misses the crucial reality that search engines never see huge swaths of the regular internet either—such as email traffic, online gaming activity, streaming video services, documents shared within corporations or on data-sharing services like Dropbox, academic and news articles behind paywalls, interactive databases and even posts on social media sites. Ultimately, though, the dark web is indeed searchableas I explain in a chapter of my book.
Thus, as I suggest, a more accurate connotation of “dark” in “dark web” is found in the phrase “going dark”—moving communications out of clear and public channels and into encrypted or more private ones.
MANAGING ANXIETIES
Focusing all this fear and moral judgment on the dark web risks both needlessly scaring people about online safety and erroneously reassuring them about online safety.
For instance, the financial services company Experian sells services that purport to “monitor the dark web” to alert customers when their personal data has been compromised by hackers and offered for sale online. Yet to sign up for that service, customers have to give the company all sorts of personal information—including their Social Security number and email address—the very data they’re seeking to protect. And they have to hope that Experian doesn’t get hacked, as its competitor Equifax was, compromising the personal data of nearly every adult in the U.S.
It’s inaccurate to assume that online crime is based on the dark web—or that the only activity on the dark web is dangerous and illegal. It’s also inaccurate to see the dark web as content beyond the reach of search engines. Acting on these incorrect assumptions would encourage governments and corporations to want to monitor and police online activity—and risk giving public support to privacy-invading efforts.
Physicists say this futuristic, super-secure network could be useful long before it reaches technological maturity
A future ‘quantum internet’ could find use long before it reaches technological maturity, a team of physicists predicts.
Such a network, which exploits the unique effects of quantum physics, would be fundamentally different to the classical Internet we use today, and research groups worldwide are already working on its early stages of development. The first stages promise virtually unbreakable privacy and security in communications; a more mature network could include a range of applications for science and beyond that aren’t possible with classical systems, including quantum sensors that can detect gravitational waves.
THE QUANTUM DIFFERENCE
The researchers argue that the technology, which would complement rather than replace the existing Internet, could eventually become widespread both for large users, such as university laboratories, and for individual consumers, although they do not give a time scale.
This stands in contrast with quantum computers, they say—another futuristic technology that physicists are feverishly working on, aiming to build machines that can outperform classical computers. “In the quantum-computing domain, it’s much more all or nothing,” says theoretical physicist Stephanie Wehner, who co-authored the paper with her Delft colleagues David Elkouss and Ronald Hanson.
Stefanie Barz, a quantum physicist at the University of Stuttgart in Germany, agrees. It’s difficult to predict which technology will come first, she and others say—a widely adopted quantum internet or useful quantum computers. But quantum networks have a big advantage, Barz says, in that “such a network can be built step by step, and different functionality can be added in each step”.
The roadmap also aims to establish a common language for a field that involves researchers with disparate backgrounds, including information technology, computer science, engineering and physics. “People talk about quantum networks to mean vastly different things,” says Hanson, an experimental physicist who is co-leading the Delft group’s push to build a quantum-internet demonstration that will link four Dutch cities.
Rodney Van Meter, a quantum network engineer at Keio University in Tokyo, says that the paper helps to clarify the field’s goals. “It gives us a new vocabulary for understanding what we are developing.” And the way the document spells out the applications can also help researchers explain their proposals to potential investors, he says. “With this roadmap, we can have this conversation.”
SIX STAGES
Quantum networks and quantum computing share many concepts and techniques. Both take advantage of phenomena that have no analogue in classical physics: for example, a quantum particle such as an electron or a photon can be in one of two well-defined states of spinning, clockwise or anticlockwise—but also in a simultaneous combination of both, called a superposition. And two particles can be ‘entangled’, in which they share a common quantum state. This makes them act in seemingly coordinated ways (such as spinning in opposite directions) even when they are separated by vast distances.
The Delft team has laid out six stages for the evolution of the quantum internet.
The first—which they say is a sort of stage 0 because it does not describe a true quantum internet—is a network that enables users to establish a common encryption key, so that they can share their (classical) data securely. The quantum physics occurs only behind the scenes: the service provider uses it to create the key. But the provider also knows the key, which means that users have to trust it. This type of network already exists, most notably in China, where it extends over some 2,000 kilometres and connects major cities including Beijing and Shanghai.
In stage 1, users will start getting into the quantum game, in which a sender creates quantum states, typically for photons. These would be sent to a receiver, either along an optical fibre or through a laser pulse beamed across open space. At this stage, any two users will be able to create a private encryption key that only they know.
The technology will also enable users to submit a quantum password, for example, to a machine such as an ATM. The machine will be able to verify the password without knowing what it is or being able to steal it.
Stage 1 has not been tried on a large scale, but it is already technologically feasible at the scale of small cities, Wehner says, although it would be very slow. A group led by Pan Jian-Wei at the University of Science and Technology of China in Hefei made the world record for this kind of transmission in 2017, when they used a satellite to link two laboratories more than 1,200 kilometres apart.
In stage 2, the quantum internet will harness the powerful phenomenon of entanglement. Its first goal will be to make quantum encryption essentially unbreakable. Most of the techniques that this stage requires already exist, at least as rudimentary lab demonstrations.
Stages 3 to 5 will, for the first time, enable any two users to store and exchange quantum bits, or qubits. These are units of quantum information, similar to classical 1s and 0s, but they can be in a superposition of both 1 and 0 simultaneously. Qubits are also the basis for quantum computation. (A number of laboratories—both in academia and at large corporations, such as IBM or Google—have been building increasingly complex quantum computers; the most advanced ones have memories that can hold a few dozen qubits.)
Getting to the final stage will require several breakthroughs. Hanson’s team has been at the forefront of these efforts, and is among those working to build the first ‘quantum repeater’—a device that can help to entangle qubits over larger and larger distances.
CLOCKS AND BALLOTS
The early adopters of the highest-stage networks will probably be scientists themselves. Labs will get to connect to the first advanced quantum computers remotely, or to link up such machines to work as a single computer.
They could then use these systems to perform experiments that aren’t possible with classical machines, for example, simulating the quantum physics of molecules or materials. Networks of quantum clocks could dramatically increase the precision of measurements for phenomena such as gravitational waves, and distant optical telescopes could link up their qubits to sharpen images.
But there could be applications outside of science, too. In an election, a stage-5 quantum internet could allow voters to select not just one candidate, but a ‘superposition’ of candidates, which includes, say, their second-favourite option. “Quantum voters,” says physicist Nicole Yunger Halpern at the Harvard-Smithsonian Center for Astrophysics in Cambridge, Massachusetts, could use “strategic-voting schemes that classical voters can’t implement”. And quantum techniques might help large groups to coordinate and reach a consensus, for example, to validate electronic currencies such as Bitcoin.
Liang Jiang, a theoretical physicist at Yale University in New Haven, Connecticut, says that the roadmap will be useful to the broader quantum community, but that it focuses mostly on the types of technology that the Delft group has adopted. For example, theoretical work published last year by Jiang and collaborators suggests that small- or medium-scale networks could be based on microwaves rather than laser pulses.
Researchers’ opinions are not unanimous as to whether these applications will truly be useful, or whether a quantum internet will ever be sophisticated enough to make them broadly available. But some are optimistic. “I have no doubt that it will exist at some point,” Wehner says. But, she adds, “I think it is going to take a long time”.